
自动微分机制介绍¶
PaddlePaddle的神经网络核心是自动微分,本篇文章主要为你介绍如何使用飞桨的自动微分,以及飞桨的自动微分机制,帮助你更好的使用飞桨进行训练。
一、背景¶
神经网络是由节点和节点间的相互连接组成的。网络中每层的每个节点代表一种特定的函数,来对输入进行计算。每个函数都是由不同参数(权重w和偏置b)组成。神经网络训练的过程,就是不断让这些函数的参数进行学习、优化,以能够更好的处理后面输入的过程。
为了让神经网络的判断更加准确,首先需要有衡量效果的工具,于是损失函数应运而生。如果你想要神经网络的效果好,那么就要让损失函数尽可能的小,于是深度学习引入了能够有效计算函数最小值的算法–梯度下降等优化算法,以及参数优化更新过程–反向传播。
前向传播是输入通过每一层节点计算后得到每层输出,上层输出又作为下一层的输入,最终达到输出层。然后通过损失函数计算得到loss值。
反向传播是通过loss值来指导前向节点中的函数参数如何改变,并更新每层中每个节点的参数,来让整个神经网络达到更小的loss值。
自动微分机制就是让你只关注组网中的前向传播过程,然后飞桨框架来自动完成反向传播过程,从而来让你从繁琐的求导、求梯度的过程中解放出来。
二、如何使用飞桨的自动微分机制¶
本文通过一个比较简单的模型来还原飞桨的自动微分过程。 本示例基于Paddle2.0编写。
#加载飞桨和相关类库
import paddle
from paddle.vision.models import vgg11
import paddle.nn.functional as F
import numpy as np
print(paddle.__version__)
2.1.1
本案例首先定义网络。因为本示例着重展示如何使用飞桨进行自动微分,故组网部分不过多展开,直接使用高层API中封装好的模型vgg11。
然后随机初始化一个输入x,和对应标签label。
model = vgg11()
x = paddle.rand([1,3,224,224])
label = paddle.randint(0,1000)
然后将输入传入到模型中,进行前向传播过程。
# 前向传播
predicts = model(x)
前向传播结束后,你就得到模型的预测结果predicts,这时可以使用飞桨中的对应损失函数API进行损失函数的计算。该例子中使用cross_entropy来计算损失函数,来衡量模型的预测情况。
# 计算损失
loss = F.cross_entropy(predicts, label)
随后进行反向传播,在飞桨中你只需要调用backward()即可自动化展开反向传播过程。各梯度保存在grad属性中。
# 开始进行反向传播
loss.backward()
然后来定义优化器,本例子中使用Adam优化器,设置learning_rate为0.001,并把该模型的所有参数传入优化器中。
# 设置优化器
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
最后通过step来开始执行优化器,并进行模型参数的更新
# 更新参数
optim.step()
通过以上步骤,你已经完成了一个神经网络前向传播、反向传播的所有过程。快自己动手试试吧!
三、飞桨中自动微分相关所有的使用方法说明¶
此章主要介绍飞桨中所有自动微分过程中会使用到的方法、属性等。属于第二部分的扩展阅读。
1、飞桨中的Tensor有stop_gradient属性,这个属性可以查看一个Tensor是否计算并传播梯度。
如果为
True,则该Tensor不会计算梯度,并会阻绝Autograd的梯度传播。反之,则会计算梯度并传播梯度。用户自行创建的的
Tensor,默认stop_gradient为True,即默认不计算梯度;模型参数的stop_gradient默认都为False,即默认计算梯度。
import paddle
a = paddle.to_tensor([1.0, 2.0, 3.0])
b = paddle.to_tensor([1.0, 2.0, 3.0], stop_gradient=False) # 将b设置为需要计算梯度的属性
print(a.stop_gradient)
print(b.stop_gradient)
True
False
a.stop_gradient = False
print(a.stop_gradient)
False
2、接下来,本文用一个简单的计算图来了解如何调用backward()函数。开始从当前Tensor开始计算反向的神经网络,传导并计算计算图中Tensor的梯度。
import paddle
x = paddle.to_tensor([1.0, 2.0, 3.0], stop_gradient=False)
y = paddle.to_tensor([4.0, 5.0, 6.0], stop_gradient=False)
z = x ** 2 + 4 * y
假设上面创建的x和y分别是神经网络中的参数,z为神经网络的损失值loss。
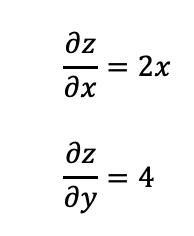
对z调用backward(),飞桨即可以自动计算x和y的梯度,并且将他们存进grad属性中。
z.backward()
print("Tensor x's grad is: {}".format(x.grad))
print("Tensor y's grad is: {}".format(y.grad))
Tensor x's grad is: [2. 4. 6.]
Tensor y's grad is: [4. 4. 4.]
此外,飞桨默认会释放反向计算图。如果在backward()之后继续添加OP,需要将backward()中的retain_graph参数设置为True,此时之前的反向计算图会保留。
温馨小提示:将其设置为False会更加节省内存。因为他的默认值是False,所以也可以直接不设置此参数。
import paddle
x = paddle.to_tensor([1.0, 2.0, 3.0], stop_gradient=False)
y = x + 3
y.backward(retain_graph=True) # 设置retain_graph为True,保留反向计算图
print("Tensor x's grad is: {}".format(x.grad))
Tensor x's grad is: [1. 1. 1.]
3、因为backward()会累积梯度,所以飞桨还提供了clear_grad()函数来清除当前Tensor的梯度。
import paddle
import numpy as np
x = np.ones([2, 2], np.float32)
inputs2 = []
for _ in range(10):
tmp = paddle.to_tensor(x)
tmp.stop_gradient = False
inputs2.append(tmp)
ret2 = paddle.add_n(inputs2)
loss2 = paddle.sum(ret2)
loss2.backward()
print("Before clear {}".format(loss2.gradient()))
loss2.clear_grad()
print("After clear {}".format(loss2.gradient()))
Before clear [1.]
After clear [0.]
四、飞桨自动微分运行机制¶
本章主要介绍飞桨在实现反向传播进行自动微分计算时,内部是如何运行工作的。此部分为选读部分,更多是介绍飞桨内部实现机制,可以选择跳过,跳过不会影响你的正常使用。
飞桨的自动微分是通过trace的方式,记录前向OP的执行,并自动创建反向var和添加相应的反向OP,然后来实现反向梯度计算的。
下面本文用一些的例子,来模拟这个过程。
例子一:首先用一个比较简单的例子来让你了解整个过程。
import paddle
a = paddle.to_tensor(2.0, stop_gradient=False)
b = paddle.to_tensor(5.0, stop_gradient=True)
c = a * b
c.backward()
print("Tensor a's grad is: {}".format(a.grad))
print("Tensor b's grad is: {}".format(b.grad))
Tensor a's grad is: [5.]
Tensor b's grad is: None
在上面代码中c.backward()执行前,你可以理解整个计算图是这样的:
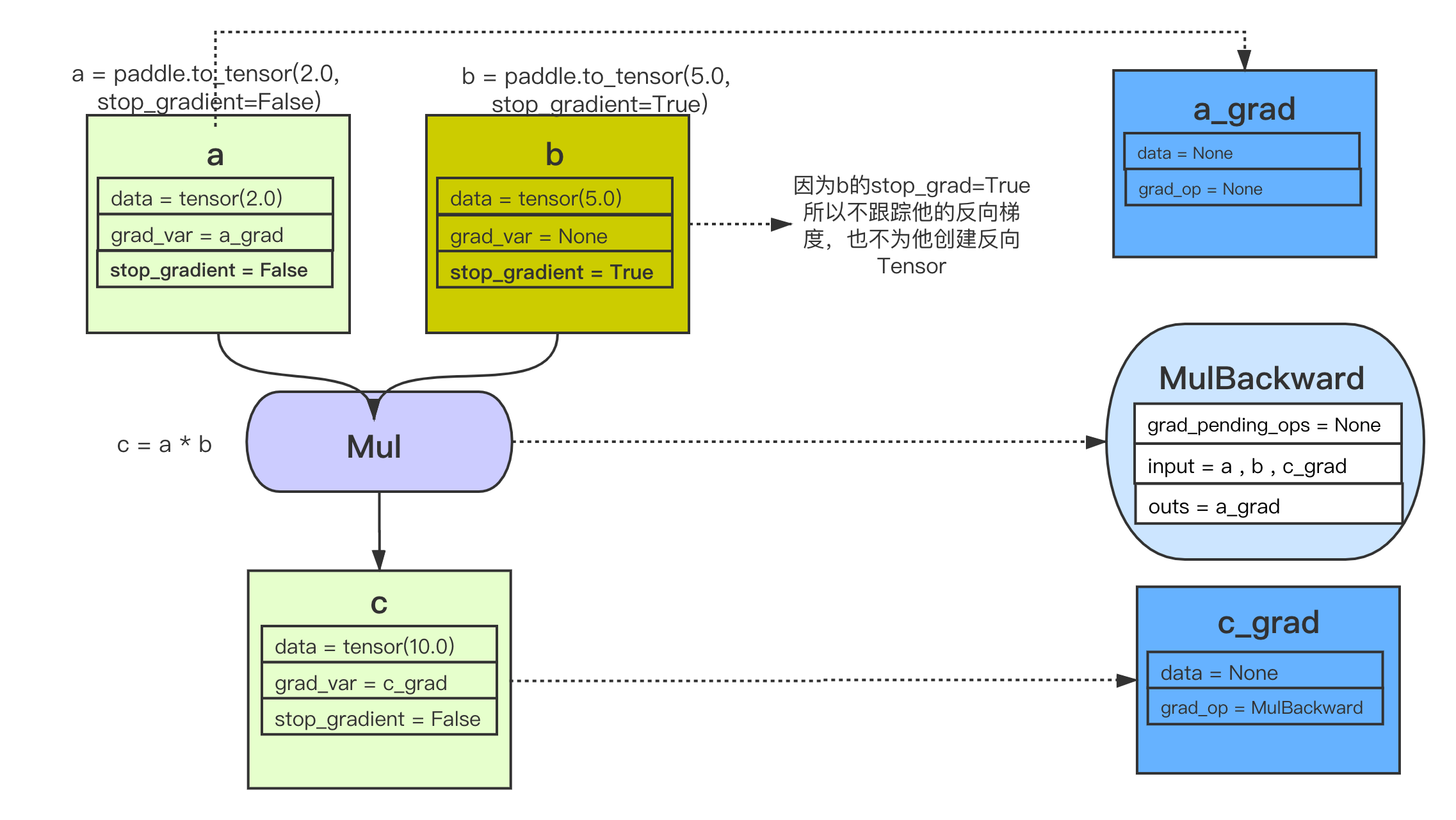
当创建Tensor,Tensor的stop_grad=False时,会自动为此Tensor创建一个反向Tensor。在此例子中,a的反向Tensor就是a_grad。在a_grad中,会记录他的反向OP,因为a没有作为任何反向op的输入,所以它的grad_op为None。
当执行OP时,会自动创建反向OP,不同的OP创建反向OP的方法不同,传的内容也不同。本文以这个乘法OP为例:
-乘法OP的反向OP,即MulBackward的输入是,正向OP的两个输入,以及正向OP的输出Tensor的反向Tensor。在此例子中就是,a、b、c_grad
-乘法OP的反向OP,即MulBackward的输出是,正向OP的两个输入的反向Tensor(如果输入是stop_gradient=True,则即为None)。在此例子中就是,a_grad、None(b_grad)
-乘法OP的反向OP,即MulBackward的grad_pending_ops是自动构建反向网络的时候,让这个反向op知道它下一个可以执行的反向op是哪一个,可以理解为反向网络中,一个反向op指向下一个反向op的边。
当c通过乘法OP被创建后,c会创建一个反向Tensor:c_grad,他的grad_op为该乘法OP的反向OP,即MulBackward。
调用backward()后,正式开始进行反向传播过程,开始自动计算微分。
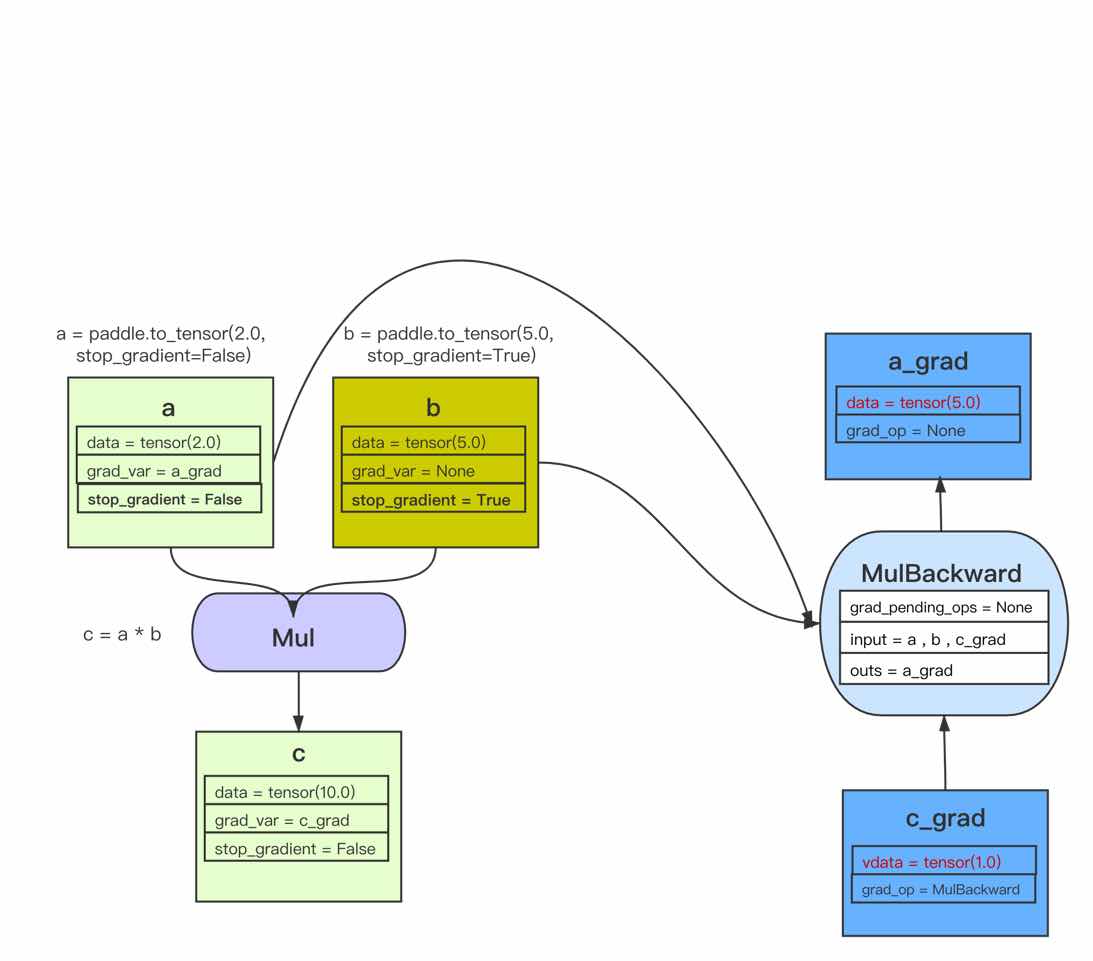
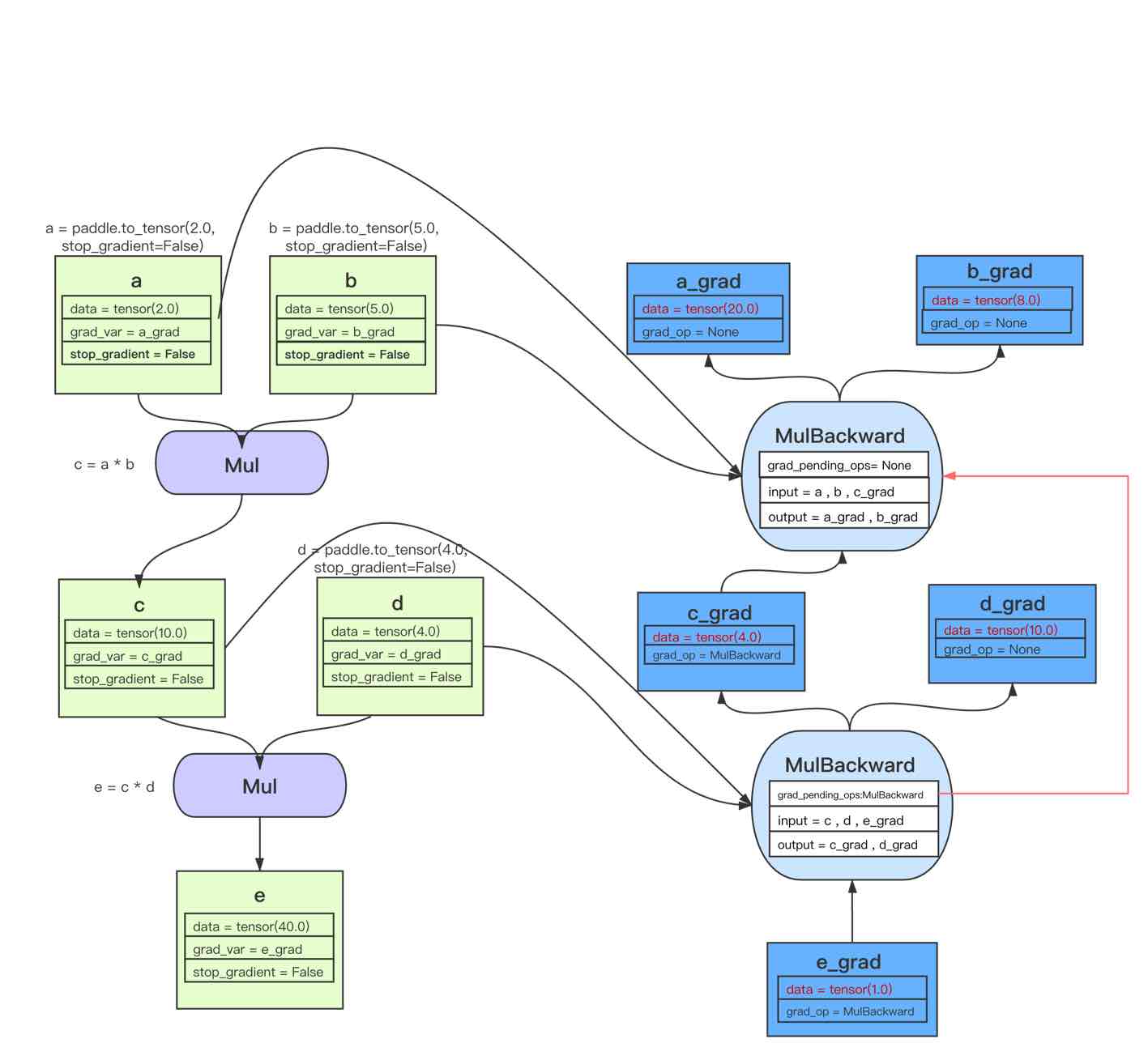
例子二:用一个稍微复杂一点的例子让你深入了解这个过程。
import paddle
a = paddle.to_tensor(2.0, stop_gradient=False)
b = paddle.to_tensor(5.0, stop_gradient=False)
c = a * b
d = paddle.to_tensor(4.0, stop_gradient=False)
e = c * d
e.backward()
print("Tensor a's grad is: {}".format(a.grad))
print("Tensor b's grad is: {}".format(b.grad))
print("Tensor c's grad is: {}".format(c.grad))
print("Tensor d's grad is: {}".format(d.grad))
Tensor a's grad is: [20.]
Tensor b's grad is: [8.]
Tensor c's grad is: [4.]
Tensor d's grad is: [10.]
该例子的正向和反向图构建过程即:
五、总结¶
本文章主要介绍了如何使用飞桨的自动微分,以及飞桨的自动微分机制。