自动混合精度训练(AMP)¶
一般情况下,训练深度学习模型时默认使用的数据类型(dtype)是 float32,每个数据占用 32 位的存储空间。为了节约显存消耗,业界提出了 16 位的数据类型(如 GPU 支持的 float16、bfloat16),每个数据仅需要 16 位的存储空间,比 float32 节省一半的存储空间,并且一些芯片可以在 16 位的数据上获得更快的计算速度,比如按照 NVIDIA 的数据显示,V100 GPU 上 矩阵乘和卷积计算在 float16 的计算速度最大可达 float32 的 8 倍。
考虑到一些算子(OP)对数据精度的要求较高(如 softmax、cross_entropy),仍然需要采用 float32 进行计算;还有一些算子(如 conv2d、matmul)对数据精度不敏感,可以采用 float16 / bfloat16 提升计算速度并降低存储空间,飞桨框架提供了自动混合精度(Automatic Mixed Precision,以下简称为 AMP)训练的方法,可在模型训练时,自动为算子选择合适的数据计算精度(float32 或 float16 / bfloat16),在保持训练精度(accuracy)不损失的条件下,能够加速训练,可参考 2018 年百度与 NVIDIA 联合发表的论文:MIXED PRECISION TRAINING。本文将介绍如何使用飞桨框架实现自动混合精度训练。
目前,在计算机视觉、自然语言处理等多个领域的任务上,飞桨的自动混合精度训练技术不仅提升了模型的训练性能,并且可以达到精度无损。以下是飞桨部分模型套件中使用 float16 训练的模型,在这些模型上使用几乎纯 float16 训练的 AMP-O2 优化级别,达到了和 float32 相同的训练效果。
| 图像分类 | 物体分割/检测 | 文字识别/文档分析 |
| ResNet50 | PP-HumanSeg-Lite | ch_PP-OCRv2_rec |
| MobileNetV3 | PP-Matting | layoutxlm_ser |
| SwinTransformer | OCRNet | vi_layoutxlm_ser |
| PP-HGNet | PP-LiteSeg(STDC-1) | 自然语言处理 |
| PP-LCNetV2 | YOLOv3 | ERNIE-Tiny |
| PPLCNet | 视频分类 | BERT |
| PP-ShiTu | PP-TSM | Transformer |
一、概述¶
1.1 浮点数据类型¶
Float16 和 bfloat16(brain floating point)都是一种半精度浮点数据类型,在计算机中使用 2 字节(16 位)存储。与计算中常用的单精度浮点数(float32)和双精度浮点数(float64)类型相比,float16 及 bfloat16 更适于在精度要求不高的场景中使用。
对比 float32 与 float16 / bfloat16 的浮点格式,如图 1 所示:
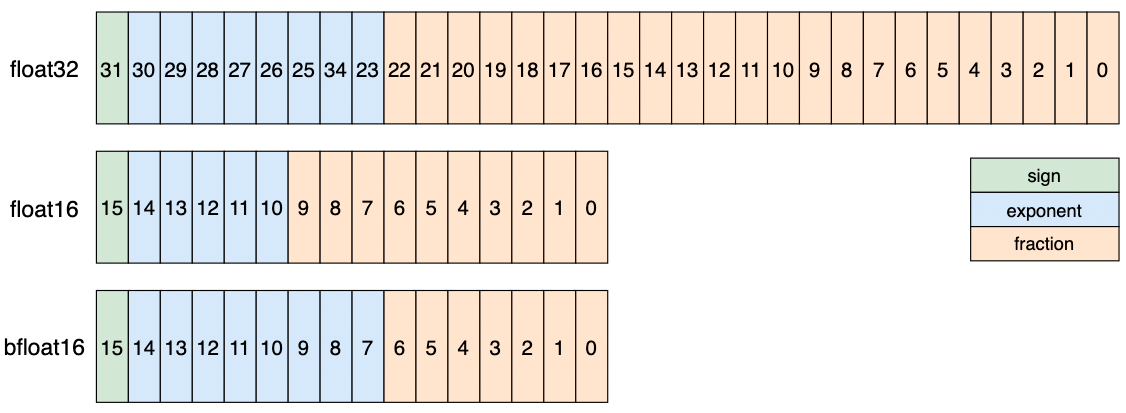
上述数据类型存在如下数值特点:
float32 的指数位占 8 位,尾数位占 23 位,可表示的数据动态范围是[2^-126, 2^127],是深度学习模型时默认使用的数据类型。
float16 的指数位占 5 位,尾数位占 10 位,相比 float32,可表示的数据动态范围更低,最小可表示的正数数值为 2^-14,最大可表示的数据为 65504,容易出现数值上溢出问题。
bfloat16 的指数位 8 位,尾数为 7 位,其特点是牺牲精度从而获取更大的数据范围,可表示的数据范围与 float32 一致,但是与 float16 相比 bfloat16 可表示的数据精度更低,相比 float16 更易出现数值下溢出的问题。
1.2 AMP 计算过程¶
1.2.1 auto_cast 策略¶
飞桨框架采用了 auto_cast 策略实现模型训练过程中计算精度的自动转换及使用。通常情况下,模型参数使用单精度浮点格式存储(float32),在训练过程中,将模型参数从单精度浮点数(float32)转换为半精度浮点数(float16 或 bfloat16)参与前向计算,并得到半精度浮点数表示中间状态,然后使用半精度浮点数计算参数梯度,最后将参数梯度转换为单精度浮点数格式后,更新模型参数。计算过程如下图 2 所示:
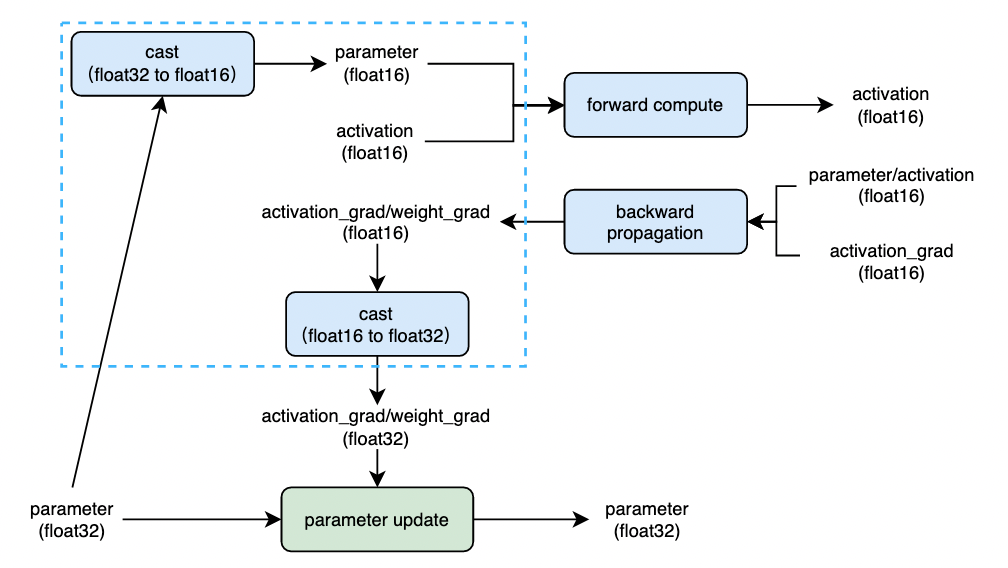
上图中蓝色虚线框内的逻辑即是 AMP 策略下参数精度转换(cast)逻辑,通常 cast 操作所带来的开销是有限的,当使用 float16 / bfloat16 在前向计算(forward compute)及反向传播(backward propagation)过程中取得的计算性能收益大于 cast 所带来的开销时,开启 AMP 训练将得到更优的训练性能。
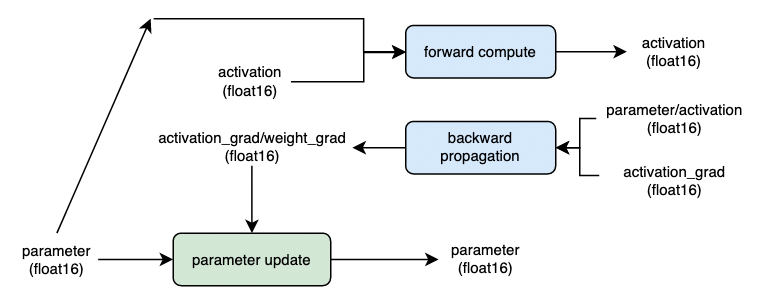
当模型参数在训练前即使用半精度浮点格式存数时(float16 / bfloat16),训练过程中将省去图 2 中的 cast 操作,可进一步提升模型训练性能,但是需要注意模型参数采用低精度数据类型进行存储,可能对模型最终的训练精度带来影响。计算过程如下图 3 所示:
1.2.2 grad_scaler 策略¶
如 1.1 所述,半精度浮点数的表示范围远小于单精度浮点数的表示范围,在深度学习领域,参数、中间状态和梯度的值通常很小,因此以半精度浮点数参与计算时容易出现数值下溢(underflow)的情况,即接近零的值下溢为零值。为了避免这个问题,飞桨采用 grad_scaler 策略。主要内容是:对训练 loss 乘以一个称为 loss_scaling 的缩放值,根据链式法则,在反向传播过程中,参数梯度也等价于相应地乘以了 loss_scaling 的值,在参数更新时再将梯度值相应地除以 loss_scaling 的值。
然而,在模型训练过程中,选择合适的 loss_scaling 值是个较大的挑战,因此,飞桨提供了 动态 loss_scaling 的机制:
训练开始前,为 loss_scaling 设置一个较大的初始值 init_loss_scaling,默认为 2.^15,并设置 4 个用于动态调整 loss_scaling 大小的参数:incr_ratio=2.0、decr_ratio=0.5、incr_every_n_steps=1000、decr_every_n_nan_or_inf=2;
启动训练后,在每次计算完成梯度后,对所有的梯度之进行检查,判断是否存在 nan/inf 并记录连续出现 nan/inf 的次数或连续未出现 nan/inf 的次数;
当连续 incr_every_n_step 次迭代未出现 nan/inf 时,将 loss_scaling 乘 incr_ratio;
当连续 decr_every_n_nan_or_inf 次迭代出现 nan/inf 时,将 loss_scaling 乘 decr_ratio;
1.3 支持硬件说明¶
飞桨框架支持如下硬件的混合精度训练,不同硬件已经支持的数据精度如下表所示:
| 硬件 | 支持的混合精度 | |
| Nvidia GPU | float16 | bfloat16 |
| Intel CPU | bfloat16 | |
| 华为 NPU | float16 | |
| 昆仑芯 XPU | float16 | |
| 寒武纪 MLU | float16 | |
以 Nvidia GPU 为例,介绍硬件加速机制:
在使用相同的超参数下,混合精度训练使用半精度浮点(float16 / bfloat16)和单精度(float32)浮点可达到与使用纯单精度(float32)训练相同的准确率,并可加速模型的训练速度,这主要得益于 Nvidia 从 Volta 架构开始推出的 Tensor Core 技术。
在使用 float16 计算时具有如下特点:
float16 可降低一半的内存带宽和存储需求,这使得在相同的硬件条件下,可使用更大更复杂的模型以及更大的 batch size 大小。
float16 可以充分利用 Nvidia Volta、Turing、Ampere 架构 GPU 提供的 Tensor Cores 技术。在相同的 GPU 硬件上,Tensor Core 的 float16 计算吞吐量是 float32 的 8 倍。
从 NVIDIA Ampere 架构开始,GPU 支持 bfloat16,其计算性能与 float16 持平。
说明:通过
nvidia-smi指令可帮助查看 NVIDIA 显卡架构信息,混合精度训练适用的 NVIDIA GPU 计算能力至少为 7.0 的版本。此外如果已开启自动混合精度训练,飞桨框架会自动检测硬件环境是否符合要求,如不符合则将提供类似如下的警告信息:UserWarning: AMP only support NVIDIA GPU with Compute Capability 7.0 or higher, current GPU is: Tesla K40m, with Compute Capability: 3.5.。
1.4 适用场景说明¶
混合精度训练想要取得较高的收益通常都是在显存利用率较高的场景下,具体地讲就是模型中存在计算负载较大的 matmul、conv 等算子。如果模型本身上述算子的占比较小,那么混合精度取得的收益十分有限,同时为了引入混合精度训练还会带来精度转换(cast)的开销。
二、动态图训练开启 AMP 示例¶
使用飞桨框架提供的 API,能够在原始训练代码基础上快速开启自动混合精度训练,并根据设定的策略,在训练时相关算子(OP)的计算中,自动选择 float16 或 float32 进行计算。
依据 float16 数据类型在模型中的使用程度划分,飞桨框架的混合精度策略分为两个等级:
Level = ‘O1’:采用黑白名单策略进行混合精度训练,黑名单中的 OP 将采用 float32 计算,白名单中的 OP 将采用 float16 计算,auto_cast 策略会自动将白名单 OP 的输入参数数据类型从 float32 转为 float16。飞桨框架默认设置了 黑白名单 OP 列表,对于不在黑白名单中的 OP,会依据该 OP 的全部输入数据类型进行推断,当全部输入均为 float16 时,OP 将直接采用 float16 计算,否则采用 float32 计算。计算逻辑可参考图 2。
Level = ‘O2’:采用了比 O1 更为激进的策略,除了框架不支持 float16 计算的 OP 以及 O2 模式下自定义黑名单中的 OP,其他全部采用 float16 计算,此外,飞桨框架提供了将网络参数从 float32 转换为 float16 的接口,相比 O1 将进一步减少 auto_cast 逻辑中的 cast 操作,训练速度会有更明显的提升,但可能影响训练精度。计算逻辑可参考图 3。
飞桨框架推荐使用动态图模式训练模型,下面以动态图模式下单卡(GPU)训练场景为例,分别介绍使用基础 API 和高层 API 开启 AMP 训练的不同使用方式。
2.1 使用基础 API¶
飞桨框架在动态图模式下实现 AMP 训练,通常需要组合 paddle.amp.auto_cast 和 paddle.amp.GradScaler API 使用。
paddle.amp.auto_cast:创建上下文环境,开启自动混合精度策略。paddle.amp.GradScaler:用于控制 loss 缩放比例,规避浮点数下溢问题。
另外在自动混合精度策略设置为 Level = ‘O2’ 模式时,除了使用以上两个 API,同时使用 paddle.amp.decorate API 将网络参数从 float32 转换为 float16, 减少 auto_cast 逻辑中的 cast 操作。
2.1.1 动态图 float32 训练¶
本例作为参照组,先执行一个普通的 float32 训练,用于对比 AMP 训练的加速效果。
1)构建一个神经网络
为了更明显地对比出 AMP 训练所能带来的性能提升,构建一个由多达九层 Linear 组成的神经网络,每层Linear网络由matmul算子及add算子组成,其中matmul算子是 float16 数据下加速效果比较好的算子。
import time
import paddle
import paddle.nn as nn
import numpy
paddle.seed(100)
numpy.random.seed(100)
place = paddle.CUDAPlace(0)
# 定义神经网络 SimpleNet,该网络由九层 Linear 组成
class SimpleNet(paddle.nn.Layer):
def __init__(self, input_size, output_size):
super().__init__()
# 九层 Linear,每层 Linear 网络由 matmul 算子及 add 算子组成
self.linears = paddle.nn.LayerList(
[paddle.nn.Linear(input_size, output_size) for i in range(9)])
def forward(self, x):
for i, l in enumerate(self.linears):
x = self.linears[i](x)
return x
2)设置训练的相关参数及训练数据
将input_size 、 output_size 和batch_size的值设为较大的值,尽可能占满显存,可更明显地对比 AMP 训练加速效果;根据 Tensor Core 的使用建议,当矩阵维数是 8 的倍数时,float16 精度下加速效果更优,因此将batch_size设置为 8 的倍数。
epochs = 2
input_size = 8192 # 设为较大的值,可更明显地对比 AMP 训练加速效果
output_size = 8192 # 设为较大的值,可更明显地对比 AMP 训练加速效果
batch_size = 2048 # batch_size 为 8 的倍数加速效果更优
nums_batch = 10
# 定义 Dataloader
from paddle.io import Dataset
class RandomDataset(Dataset):
def __init__(self, num_samples):
self.num_samples = num_samples
def __getitem__(self, idx):
data = numpy.random.random([input_size]).astype('float32')
label = numpy.random.random([output_size]).astype('float32')
return data, label
def __len__(self):
return self.num_samples
dataset = RandomDataset(nums_batch * batch_size)
loader = paddle.io.DataLoader(dataset, batch_size=batch_size, shuffle=False, drop_last=True, num_workers=0)
3)执行训练并记录训练时长
mse = paddle.nn.MSELoss() # 定义损失计算函数
model = SimpleNet(input_size, output_size) # 定义 SimpleNet 模型
optimizer = paddle.optimizer.SGD(learning_rate=0.0001, parameters=model.parameters()) # 定义 SGD 优化器
train_time = 0 # 记录总训练时长
for epoch in range(epochs):
for i, (data, label) in enumerate(loader):
start_time = time.time() # 记录开始训练时刻
label._to(place) # 将 label 数据拷贝到 gpu
# 前向计算(9 层 Linear 网络,每层由 matmul、add 算子组成)
output = model(data)
# loss 计算
loss = mse(output, label)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
optimizer.clear_grad(set_to_zero=False)
# 记录训练 loss 及训练时长
train_loss = loss.numpy()
train_time += time.time() - start_time
print("loss:", train_loss)
print("使用 float32 模式训练耗时:{:.3f} sec".format(train_time/(epochs*nums_batch)))
# loss: [0.6486028]
# 使用 float32 模式训练耗时:0.529 sec
注:如果该示例代码在你的机器上显示显存不足相关的错误,请尝试将
input_size、output_size、batch_size调小。
2.1.2 动态图 AMP-O1 训练¶
使用 AMP-O1 训练,需要在 float32 训练代码的基础上添加两处逻辑:
逻辑 1:使用
paddle.amp.auto_cast创建 AMP 上下文环境,开启自动混合精度策略Level = ‘O1’。在该上下文环境影响范围内,框架会根据预设的黑白名单,自动确定每个 OP 的输入数据类型(float32 或 float16 / bfloat16)。也可以在该 API 中添加自定义黑白名单 OP 列表。逻辑 2:使用
paddle.amp.GradScaler控制 loss 缩放比例,规避浮点数下溢问题。在模型训练过程中,框架默认开启动态 loss scaling 机制(use_dynamic_loss_scaling=True),具体介绍见 1.2.2 grad_scaler 策略。
mse = paddle.nn.MSELoss() # 定义损失计算函数
model = SimpleNet(input_size, output_size) # 定义 SimpleNet 模型
optimizer = paddle.optimizer.SGD(learning_rate=0.0001, parameters=model.parameters()) # 定义 SGD 优化器
# 逻辑 2:可选,定义 GradScaler,用于缩放 loss 比例,避免浮点数溢出,默认开启动态更新 loss_scaling 机制
scaler = paddle.amp.GradScaler(init_loss_scaling=1024)
train_time = 0 # 记录总训练时长
for epoch in range(epochs):
for i, (data, label) in enumerate(loader):
start_time = time.time() # 记录开始训练时刻
label._to(place) # 将 label 数据拷贝到 gpu
# 逻辑 1:创建 AMP-O1 auto_cast 环境,开启自动混合精度训练,将 add 算子添加到自定义白名单中(custom_white_list),
# 因此前向计算过程中该算子将采用 float16 数据类型计算
with paddle.amp.auto_cast(custom_white_list={'elementwise_add'}, level='O1'):
output = model(data) # 前向计算(9 层 Linear 网络,每层由 matmul、add 算子组成)
loss = mse(output, label) # loss 计算
# 逻辑 2:使用 GradScaler 完成 loss 的缩放,用缩放后的 loss 进行反向传播
scaled = scaler.scale(loss) # loss 缩放,乘以系数 loss_scaling
scaled.backward() # 反向传播
scaler.step(optimizer) # 更新参数(参数梯度先除系数 loss_scaling 再更新参数)
scaler.update() # 基于动态 loss_scaling 策略更新 loss_scaling 系数
optimizer.clear_grad(set_to_zero=False)
# 记录训练 loss 及训练时长
train_loss = loss.numpy()
train_time += time.time() - start_time
print("loss:", train_loss)
print("使用 AMP-O1 模式耗时:{:.3f} sec".format(train_time/(epochs*nums_batch)))
# loss: [0.6486219]
# 使用 AMP-O1 模式耗时:0.118 sec
2.1.3 动态图 AMP-O2 训练¶
使用 AMP-O2 训练,需要在 float32 训练代码的基础上添加三处逻辑:
O2 模式采用了比 O1 更为激进的策略,除了框架不支持 FP16 计算的 OP,其他全部采用 FP16 计算,需要在训练前将网络参数从 FP32 转为 FP16,在 FP32 代码的基础上添加三处逻辑:
逻辑 1:在训练前使用
paddle.amp.decorate将网络参数从 float32 转换为 float16。逻辑 2:使用
paddle.amp.auto_cast创建 AMP 上下文环境,开启自动混合精度策略Level = ‘O2’。在该上下文环境影响范围内,框架会将所有支持 float16 的 OP 均采用 float16 进行计算(自定义的黑名单除外),其他 OP 采用 float32 进行计算。逻辑 3:使用
paddle.amp.GradScaler控制 loss 缩放比例,规避浮点数下溢问题。用法与 AMP-O1 中相同。
mse = paddle.nn.MSELoss() # 定义损失计算函数
model = SimpleNet(input_size, output_size) # 定义 SimpleNet 模型
optimizer = paddle.optimizer.SGD(learning_rate=0.0001, parameters=model.parameters()) # 定义 SGD 优化器
# 逻辑 1:在 level=’O2‘模式下,将网络参数从 FP32 转换为 FP16
model = paddle.amp.decorate(models=model, level='O2')
# 逻辑 3:可选,定义 GradScaler,用于缩放 loss 比例,避免浮点数溢出,默认开启动态更新 loss_scaling 机制
scaler = paddle.amp.GradScaler(init_loss_scaling=1024)
train_time = 0 # 记录总训练时长
for epoch in range(epochs):
for i, (data, label) in enumerate(loader):
start_time = time.time() # 记录开始训练时刻
label._to(place) # 将 label 数据拷贝到 gpu
# 逻辑 2:创建 AMP-O2 auto_cast 环境,开启自动混合精度训练,前向计算过程中该算子将采用 float16 数据类型计算
with paddle.amp.auto_cast(level='O2'):
output = model(data) # 前向计算(9 层 Linear 网络,每层由 matmul、add 算子组成)
loss = mse(output, label) # loss 计算
# 逻辑 3:使用 GradScaler 完成 loss 的缩放,用缩放后的 loss 进行反向传播
scaled = scaler.scale(loss) # loss 缩放,乘以系数 loss_scaling
scaled.backward() # 反向传播
scaler.step(optimizer) # 更新参数(参数梯度先除系数 loss_scaling 再更新参数)
scaler.update() # 基于动态 loss_scaling 策略更新 loss_scaling 系数
optimizer.clear_grad(set_to_zero=False)
# 记录训练 loss 及训练时长
train_loss = loss.numpy()
train_time += time.time() - start_time
print("loss=", train_loss)
print("使用 AMP-O2 模式耗时:{:.3f} sec".format(train_time/(epochs*nums_batch)))
# loss= [0.6743]
# 使用 AMP-O2 模式耗时:0.102 sec
2.1.4 对比不同模式下训练速度¶
动态图 FP32 及 AMP 训练的精度速度对比如下表所示:
| - | float32 | AMP-O1 | AMP-O2 |
|---|---|---|---|
| 训练耗时 | 0.529s | 0.118s | 0.102s |
| loss | 0.6486028 | 0.6486219 | 0.6743 |
从上表统计结果可以看出,相比普通的 float32 训练模式, AMP-O1 模式训练速度提升约为 4.5 倍,AMP-O2 模式训练速度提升约为 5.2 倍。
注:上述实验构建了一个理想化的实验模型,其 matmul 算子占比较高,所以加速比较明显,实际模型的加速效果与模型特点有关,理论上数值计算如 matmul、conv 占比较高的模型加速效果更明显。此外,受机器环境影响,上述示例代码的训练耗时统计可能存在差异,该影响主要包括:GPU 利用率、CPU 利用率等,本示例的测试机器配置如下:
| Device | MEM Clocks | SM Clocks | Running with CPU Clocks |
|---|---|---|---|
| Tesla V100 SXM2 16GB | 877 MHz | 1530 MHz | 1000 - 2400 MHz |
2.2 使用高层 API¶
飞桨框架 2.0 开始全新推出高层 API,是对飞桨基础 API 的进一步封装与升级,提供了更加简洁易用的 API,提升了飞桨框架的易学易用性,并增强飞桨的功能。高层 API 下 AMP 使用示例如下,主要通过 paddle.Model.prepare 的 amp_configs 参数传入 AMP 相关配置。
import paddle
import paddle.nn as nn
import paddle.vision.transforms as T
def run_example_code():
device = paddle.set_device('gpu')
# 利用高层 API 定义神经网络
net = nn.Sequential(nn.Flatten(1), nn.Linear(784, 200), nn.Tanh(), nn.Linear(200, 10))
model = paddle.Model(net)
# 定义优化器
optim = paddle.optimizer.SGD(learning_rate=1e-3, parameters=model.parameters())
# 初始化神经网络
amp_configs = {
"level": "O1", # level 对应 AMP 模式:O1、O2
"custom_white_list": {'conv2d'}, # 自定义白名单,同时还支持 custom_black_list
"use_dynamic_loss_scaling": True # 动态 loss_scaling 策略
}
model.prepare(optim,
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy(),
amp_configs=amp_configs)
# 数据准备
transform = T.Compose([T.Transpose(), T.Normalize([127.5], [127.5])])
data = paddle.vision.datasets.MNIST(mode='train', transform=transform)
# 使用 amp 进行模型训练
model.fit(data, epochs=2, batch_size=32, verbose=1)
if paddle.is_compiled_with_cuda():
run_example_code()
三、其他使用场景¶
前文介绍了动态图模式下单卡(GPU)训练的方法,与之类似,分布式训练 和 动转静训练 时可以采用同样的方法开启 AMP。接下来主要介绍不同的静态图模式下开启 AMP 训练的方法,以及 AMP 训练的进阶用法,如梯度累加。
3.1 动态图下使用梯度累加¶
梯度累加是指在模型训练过程中,训练一个 batch 的数据得到梯度后,不立即用该梯度更新模型参数,而是继续下一个 batch 数据的训练,得到梯度后继续循环,多次循环后梯度不断累加,直至达到一定次数后,用累加的梯度更新参数,这样可以起到变相扩大 batch_size 的作用。受限于显存大小,可能无法开到更大的 batch_size,使用梯度累加可以实现增大 batch_size 的作用。
动态图模式天然支持梯度累加,即只要不调用梯度清零 clear_grad 方法,动态图的梯度会一直累积,在自动混合精度训练中,梯度累加的使用方式如下:
mse = paddle.nn.MSELoss() # 定义损失计算函数
model = SimpleNet(input_size, output_size) # 定义 SimpleNet 模型
optimizer = paddle.optimizer.SGD(learning_rate=0.0001, parameters=model.parameters()) # 定义 SGD 优化器
accumulate_batchs_num = 10 # 梯度累加中 batch 的数量
# 定义 GradScaler,用于缩放 loss 比例,避免浮点数溢出,默认开启动态更新 loss_scaling 机制
scaler = paddle.amp.GradScaler(init_loss_scaling=1024)
train_time = 0 # 记录总训练时长
for epoch in range(epochs):
for i, (data, label) in enumerate(loader):
start_time = time.time() # 记录开始训练时刻
label._to(place) # 将 label 数据拷贝到 gpu
# 创建 AMP-O2 auto_cast 环境,开启自动混合精度训练,前向计算过程中该算子将采用 float16 数据类型计算
with paddle.amp.auto_cast(level='O1'):
output = model(data)
loss = mse(output, label)
# 使用 GradScaler 完成 loss 的缩放,用缩放后的 loss 进行反向传播
scaled = scaler.scale(loss) # loss 缩放,乘以系数 loss_scaling
scaled.backward() # 反向传播
# 当累计的 batch 为 accumulate_batchs_num 时,更新模型参数
if (i + 1) % accumulate_batchs_num == 0:
scaler.step(optimizer) # 更新参数(参数梯度先除系数 loss_scaling 再更新参数)
scaler.update() # 基于动态 loss_scaling 策略更新 loss_scaling 系数
optimizer.clear_grad(set_to_zero=False)
# 记录训练 loss 及训练时长
train_loss = loss.numpy()
train_time += time.time() - start_time
print("loss:", train_loss)
print("使用 AMP-O1 模式耗时:{:.3f} sec".format(train_time/(epochs*nums_batch)))
# loss: [0.6602017]
# 使用 AMP-O1 模式耗时:0.113 sec
上面的例子中,每经过 accumulate_batchs_num个 batch 的训练步骤,进行 1 次参数更新。
3.2 静态图训练开启 AMP¶
飞桨框架在静态图模式下实现 AMP 训练,功能逻辑与动态图类似,只是调用的接口有区别,使用如下 API:paddle.static.amp.decorate、paddle.static.amp.fp16_guard。
paddle.static.amp.decorate:对传入的优化器进行装饰,增添 AMP 逻辑,同时可通过该接口配置 grad_scaler 策略的相关参数。paddle.static.amp.fp16_guard:在 AMP-O2 模式下,控制 float16 的作用域,只有在上下文管理器fp16_guard内部才会使用 float16 计算。
3.2.1 静态图 float32 训练¶
采用与 2.1.1 节 动态图训练相同的网络结构,静态图网络初始化如下:
paddle.enable_static() # 开启静态图模式
place = paddle.CUDAPlace(0)
# 定义静态图的 program
main_program = paddle.static.default_main_program()
startup_program = paddle.static.default_startup_program()
# 定义由 9 层 Linear 组成的神经网络
model = SimpleNet(input_size, output_size)
# 定义损失函数
mse_loss = paddle.nn.MSELoss()
静态图训练代码如下:
# 定义训练数据及标签
data = paddle.static.data(name='data', shape=[batch_size, input_size], dtype='float32')
label = paddle.static.data(name='label', shape=[batch_size, input_size], dtype='float32')
# 前向计算
predict = model(data)
# 损失计算
loss = mse_loss(predict, label)
# 定义优化器
optimizer = paddle.optimizer.SGD(learning_rate=0.0001, parameters=model.parameters())
optimizer.minimize(loss)
# 定义静态图执行器
exe = paddle.static.Executor(place)
exe.run(startup_program)
train_time = 0 # 记录总训练时长
for epoch in range(epochs):
for i, (train_data, train_label) in enumerate(loader()):
start_time = time.time() # 记录开始训练时刻
# 执行训练
train_loss = exe.run(main_program, feed={data.name: train_data, label.name: train_label }, fetch_list=[loss.name], use_program_cache=True)
# 记录训练时长
train_time += time.time() - start_time
print("loss:", train_loss)
print("使用 FP32 模式耗时:{:.3f} sec".format(train_time/(epochs*nums_batch)))
# loss: [array([0.6486028], dtype=float32)]
# 使用 FP32 模式耗时:0.531 sec
3.2.2 静态图 AMP-O1 训练¶
静态图通过paddle.static.amp.decorate 对优化器进行封装、通过paddle.static.amp.CustomOpLists 定义黑白名单,即可开启混合精度训练,示例代码如下:
# 定义训练数据及标签
data = paddle.static.data(name='data', shape=[batch_size, input_size], dtype='float32')
label = paddle.static.data(name='label', shape=[batch_size, input_size], dtype='float32')
# 前向计算
predict = model(data)
# 损失计算
loss = mse_loss(predict, label)
# 定义静态图执行器
optimizer = paddle.optimizer.SGD(learning_rate=0.0001, parameters=model.parameters())
# 1) 通过 `CustomOpLists` 自定义黑白名单
amp_list = paddle.static.amp.CustomOpLists(custom_white_list=['elementwise_add'])
# 2)通过 `decorate` 对优化器进行封装:
optimizer = paddle.static.amp.decorate(
optimizer=optimizer,
amp_lists=amp_list,
init_loss_scaling=128.0,
use_dynamic_loss_scaling=True)
optimizer.minimize(loss)
# 定义静态图执行器
exe = paddle.static.Executor(place)
exe.run(startup_program)
train_time = 0 # 记录总训练时长
for epoch in range(epochs):
for i, (train_data, train_label) in enumerate(loader()):
start_time = time.time() # 记录开始训练时刻
# 执行训练
train_loss = exe.run(main_program, feed={data.name: train_data, label.name: train_label }, fetch_list=[loss.name], use_program_cache=True)
# 记录训练时长
train_time += time.time() - start_time
print("loss:", train_loss)
print("使用 AMP-O1 模式耗时:{:.3f} sec".format(train_time/(epochs*nums_batch)))
# loss: [array([0.6486222], dtype=float32)]
# 使用 AMP-O1 模式耗时:0.117 sec
paddle.static.amp.CustomOpLists用于自定义黑白名单,将 add 算子加入了白名单中,Linear 网络将全部执行在 float16 下。
3.2.3 静态图 AMP-O2 训练¶
静态图开启 AMP-O2 有两种方式:
使用
paddle.static.amp.fp16_guard控制 float16 应用的范围,在该语境下的所有 OP 将执行 float16 计算,其他 OP 执行 float32 计算;不使用
paddle.static.amp.fp16_guard控制 float16 应用的范围,网络的全部 OP 执行 float16 计算(除去自定义黑名单的 OP、不支持 float16 计算的 OP)
1)设置paddle.static.amp.decorate的参数use_pure_fp16为 True,同时设置参数use_fp16_guard为 False。
data = paddle.static.data(name='data', shape=[batch_size, input_size], dtype='float32')
label = paddle.static.data(name='label', shape=[batch_size, input_size], dtype='float32')
predict = model(data)
loss = mse_loss(predict, label)
optimizer = paddle.optimizer.SGD(learning_rate=0.0001, parameters=model.parameters())
# 1)通过 `decorate` 对优化器进行封装,use_fp16_guard 设置为 False,网络的全部 op 执行 FP16 计算
optimizer = paddle.static.amp.decorate(
optimizer=optimizer,
init_loss_scaling=128.0,
use_dynamic_loss_scaling=True,
use_pure_fp16=True,
use_fp16_guard=False)
optimizer.minimize(loss)
exe = paddle.static.Executor(place)
exe.run(startup_program)
# 2) 利用 `amp_init` 将网络的 FP32 参数转换 FP16 参数.
optimizer.amp_init(place, scope=paddle.static.global_scope())
train_time = 0 # 记录总训练时长
for epoch in range(epochs):
for i, (train_data, train_label) in enumerate(loader()):
start_time = time.time() # 记录开始训练时刻
# 执行训练
train_loss = exe.run(main_program, feed={data.name: train_data, label.name: train_label }, fetch_list=[loss.name], use_program_cache=True)
# 记录训练时长
train_time += time.time() - start_time
print("loss:", train_loss)
print("使用 AMP-O2 模式耗时:{:.3f} sec".format(train_time/(epochs*nums_batch)))
# loss: [array([0.6743], dtype=float16)]
# 使用 AMP-O2 模式耗时:0.098 sec
注:在 AMP-O2 模式下,网络参数将从 float32 转为 float16,输入数据需要相应输入 float16 类型数据,因此需要将
class RandomDataset中初始化的数据类型设置为float16。
2)设置paddle.static.amp.decorate的参数use_pure_fp16为 True,同时设置参数use_fp16_guard为 True,通过paddle.static.amp.fp16_guard控制使用 float16 的计算范围。
在模型定义的代码中加入fp16_guard控制部分网络执行在 float16 下:
class SimpleNet(paddle.nn.Layer):
def __init__(self, input_size, output_size):
super().__init__()
self.linears = paddle.nn.LayerList(
[paddle.nn.Linear(input_size, output_size) for i in range(9)])
def forward(self, x):
for i, l in enumerate(self.linears):
if i > 0:
# 在模型定义中通过 fp16_guard 控制使用 float16 的计算范围
with paddle.static.amp.fp16_guard():
x = self.linears[i](x)
else:
x = self.linears[i](x)
return x
该模式下的训练代码如下:
data = paddle.static.data(name='data', shape=[batch_size, input_size], dtype='float32')
label = paddle.static.data(name='label', shape=[batch_size, input_size], dtype='float32')
predict = model(data)
loss = mse_loss(predict, label)
optimizer = paddle.optimizer.SGD(learning_rate=0.0001, parameters=model.parameters())
# 1)通过 `decorate` 对优化器进行封装:
optimizer = paddle.static.amp.decorate(
optimizer=optimizer,
init_loss_scaling=128.0,
use_dynamic_loss_scaling=True,
use_pure_fp16=True,
use_fp16_guard=True)
optimizer.minimize(loss)
exe = paddle.static.Executor(place)
exe.run(startup_program)
# 2) 利用 `amp_init` 将网络的 FP32 参数转换 FP16 参数.
optimizer.amp_init(place, scope=paddle.static.global_scope())
train_time = 0 # 记录总训练时长
for epoch in range(epochs):
for i, (train_data, train_label) in enumerate(loader()):
start_time = time.time() # 记录开始训练时刻
# 执行训练
train_loss = exe.run(main_program, feed={data.name: train_data, label.name: train_label }, fetch_list=[loss.name], use_program_cache=True)
# 记录训练时长
train_time += time.time() - start_time
print("loss:", train_loss)
print("使用 AMP-O2 模式耗时:{:.3f} sec".format(train_time/(epochs*nums_batch)))
# loss: [array([0.6691731], dtype=float32)]
# 使用 AMP-O2 模式耗时:0.140 sec
3.2.4 对比不同模式下训练速度¶
静态图 FP32 及 AMP 训练的精度速度对比如下表所示:
| - | FP32 | AMP-O1 | AMP-O2 |
|---|---|---|---|
| 耗时 | 0.531s | 0.117s | 0.098s |
| loss | 0.6486028 | 0.6486222 | 0.6743 |
从上表统计结果可以看出,使用自动混合精度训练 O1 模式训练速度提升约为 4.5 倍,O2 模式训练速度提升约为 5.4 倍。
四、其他注意事项¶
飞桨 AMP 提升模型训练性能的根本原因是:利用 Tensor Core 来加速 float16 下的matmul和conv等运算,为了获得最佳的加速效果,Tensor Core 对矩阵乘和卷积运算有一定的使用约束,约束如下:
通用矩阵乘 (GEMM) 定义为:
C = A * B + C,其中:A 维度为:M x K
B 维度为:K x N
C 维度为:M x N
矩阵乘使用建议如下:根据 Tensor Core 使用建议,当矩阵维数 M、N、K 是 8(A100 架构 GPU 为 16)的倍数时(FP16 数据下),性能最优。
卷积计算定义为:
NKPQ = NCHW * KCRS,其中:N 代表:batch size
K 代表:输出数据的通道数
P 代表:输出数据的高度
Q 代表:输出数据的宽度
C 代表:输入数据的通道数
H 代表:输入数据的高度
W 代表:输入数据的宽度
R 代表:滤波器的高度
S 代表:滤波器的宽度
卷积计算使用建议如下:
输入/输出数据的通道数(C/K)可以被 8 整除(FP16),(cudnn7.6.3 及以上的版本,如果不是 8 的倍数将会被自动填充)
对于网络第一层,通道数设置为 4 可以获得最佳的运算性能(NVIDIA 为网络的第一层卷积提供了特殊实现,使用 4 通道性能更优)
设置内存中的张量布局为 NHWC 格式(如果输入 NCHW 格式,Tesor Core 会自动转换为 NHWC,当输入输出数值较大的时候,这种转置的开销往往更大)
五、AMP 常见问题及处理方法¶
飞桨 AMP 常见问题及处理方法如下:
开启 AMP 训练后无加速效果或速度下降
可能原因 1:所用显卡并不支持 AMP 加速,可在训练日志中查看如下 warning 信息:
UserWarning: AMP only support NVIDIA GPU with Compute Capability 7.0 or higher, current GPU is: Tesla K40m, with Compute Capability: 3.5.;可能原因 2:模型是轻计算、重调度的类型,计算负载较大的 matmul、conv 等操作占比较低,可通过 nvidia-smi 实时查看显卡显存利用率(Memory Usage 及 GPU_Util 参数)。
针对上述原因,建议关闭混合精度训练。
AMP-O2 与分布式训练同时使用时抛出 RuntimeError:
For distributed AMP training, you should first use paddle.amp.decorate() to decotate origin model, and then call paddle.DataParallel get distributed model.原因:AMP-O2 的分布式训练,要求
paddle.amp.decorate需要声明在paddle.DataParallel初始化分布式训练的网络前。正确用法如下:
import paddle
model = SimpleNet(input_size, output_size) # 定义 SimpleNet 模型
model = paddle.amp.decorate(models=model, level='O2') # paddle.amp.decorate 需要声明在 paddle.DataParallel 前
dp_model = paddle.DataParallel(model)