安装与编译Windows预测库¶
直接下载安装¶
| 版本说明 | 预测库(1.5.1版本) |
|---|---|
| cpu_avx_mkl | fluid_inference.zip |
| cpu_avx_openblas | fluid_inference.zip |
| cuda8.0_cudnn7_avx_mkl | fluid_inference.zip |
| cuda8.0_cudnn7_avx_openblas | fluid_inference.zip |
| cuda9.0_cudnn7_avx_mkl | fluid_inference.zip |
| cuda9.0_cudnn7_avx_openblas | fluid_inference.zip |
从源码编译预测库¶
用户也可以从 PaddlePaddle 核心代码编译C++预测库,只需在编译时配制下面这些编译选项:
| 选项 | 值 |
|---|---|
| CMAKE_BUILD_TYPE | Release |
| FLUID_INFERENCE_INSTALL_DIR | 安装路径(可选) |
| ON_INFER | ON(推荐) |
| WITH_GPU | ON/OFF |
| WITH_MKL | ON/OFF |
请按照推荐值设置,以避免链接不必要的库。其它可选编译选项按需进行设定。
Windows下安装与编译预测库步骤:(在Windows命令提示符下执行以下指令)
设置预测库的安装路径,将path_to_paddle替换为PaddlePaddle预测库的安装路径:
PADDLE_ROOT=path_to_paddle(不设置则使用默认路径)将PaddlePaddle的源码clone在当下目录的Paddle文件夹中,并进入Paddle目录:
git clone https://github.com/PaddlePaddle/Paddle.gitcd Paddle
创建名为build的目录并进入:
mkdir buildcd build
执行cmake:
cmake .. -G "Visual Studio 14 2015 Win 64" -DFLUID_INFERENCE_INSTALL_DIR=${PADDLE_ROOT} -DCMAKE_BUILD_TYPE=Release -DWITH_MKL=OFF -DWITH_GPU=OFF -DON_INFER=ON-DFLUID_INFERENCE_INSTALL_DIR=$PADDLE_ROOT为可选配置选项,如未设置,则使用默认路径。-DWITH_GPU为是否使用GPU的配置选项,-DWITH_MKL为是否使用Intel MKL(数学核心库)的配置选项,请按需配置。
从
https://github.com/wopeizl/Paddle_deps下载预编译好的第三方依赖包(openblas, snappystream),将整个third_party文件夹复制到build目录下。使用Blend for Visual Studio 2015 打开
paddle.sln文件,选择平台为x64,配置为Release,先编译third_party模块,再编译inference_lib_dist模块。 操作方法:在Visual Studio中选择相应模块,右键选择"生成"(或者"build")
编译成功后,使用C++预测库所需的依赖(包括:(1)编译出的PaddlePaddle预测库和头文件;(2)第三方链接库和头文件;(3)版本信息与编译选项信息) 均会存放于PADDLE_ROOT目录中。目录结构如下:
PaddleRoot/
├── CMakeCache.txt
├── paddle
│ ├── include
│ │ ├── paddle_anakin_config.h
│ │ ├── paddle_analysis_config.h
│ │ ├── paddle_api.h
│ │ ├── paddle_inference_api.h
│ │ ├── paddle_mkldnn_quantizer_config.h
│ │ └── paddle_pass_builder.h
│ └── lib
│ ├── libpaddle_fluid.a
│ └── libpaddle_fluid.so
├── third_party
│ ├── boost
│ │ └── boost
│ ├── eigen3
│ │ ├── Eigen
│ │ └── unsupported
│ └── install
│ ├── gflags
│ ├── glog
│ ├── mkldnn
│ ├── mklml
│ ├── protobuf
│ ├── snappy
│ ├── snappystream
│ ├── xxhash
│ └── zlib
└── version.txt
version.txt 中记录了该预测库的版本信息,包括Git Commit ID、使用OpenBlas或MKL数学库、CUDA/CUDNN版本号,如:
GIT COMMIT ID: cc9028b90ef50a825a722c55e5fda4b7cd26b0d6
WITH_MKL: ON
WITH_MKLDNN: ON
WITH_GPU: ON
CUDA version: 8.0
CUDNN version: v7
编译预测demo¶
软件要求¶
请您严格按照以下步骤进行安装,否则可能会导致安装失败!
安装Visual Studio 2015 update3
安装Visual Studio 2015,安装选项中选择安装内容时勾选自定义,选择安装全部关于c,c++,vc++的功能。
编译demo¶
下载并解压 fluid_inference_install_dir.zip 压缩包。
进入 Paddle/paddle/fluid/inference/api/demo_ci 目录,新建build目录并进入,然后使用cmake生成vs2015的solution文件。 指令为:
cmake .. -G "Visual Studio 14 2015 Win64" -DWITH_GPU=OFF -DWITH_MKL=ON -DWITH_STATIC_LIB=ON -DCMAKE_BUILD_TYPE=Release -DDEMO_NAME=simple_on_word2vec -DPADDLE_LIB=path_to_the_paddle_lib
注:
-DDEMO_NAME 是要编译的文件
-DPADDLE_LIB fluid_inference_install_dir,例如 -DPADDLE_LIB=D:\fluid_inference_install_dir
Cmake可以在官网进行下载,并添加到环境变量中。
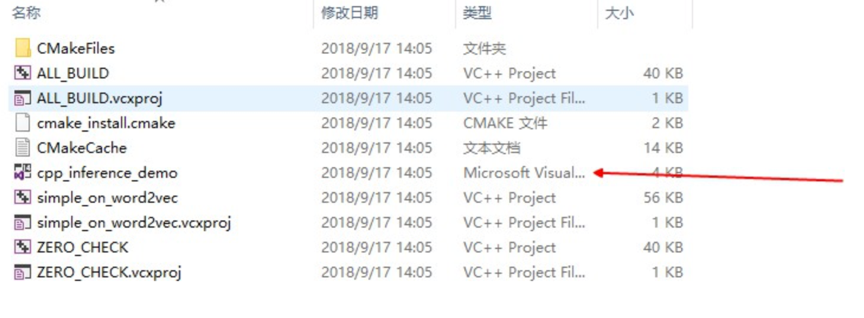
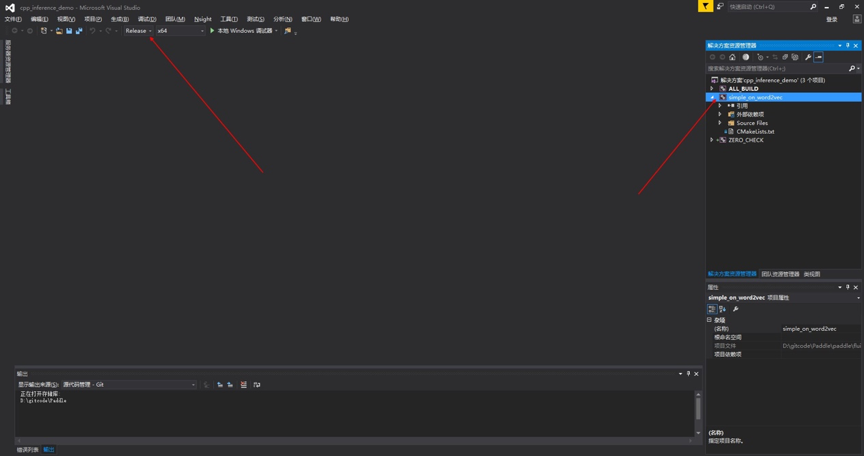
执行完毕后,build 目录如图所示,打开箭头指向的 solution 文件:
修改编译属性为 /MT :
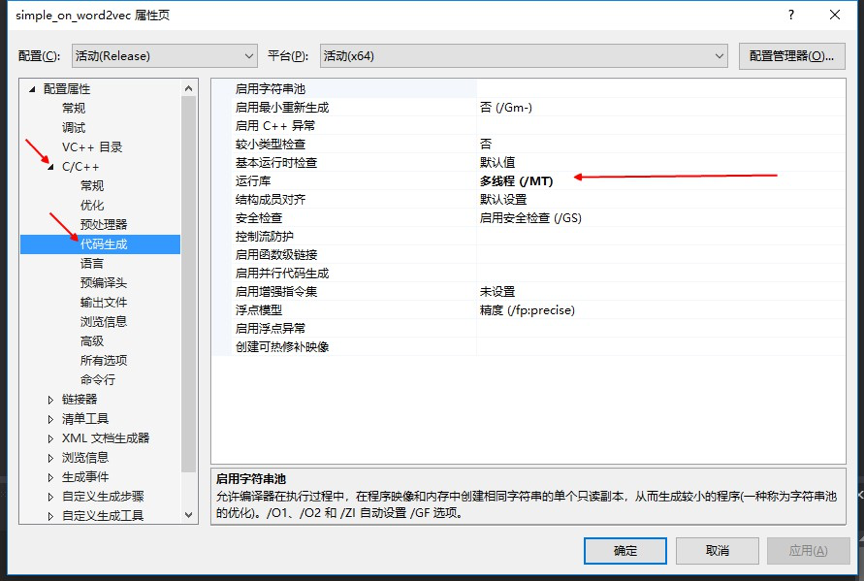
编译生成选项改成 Release 。
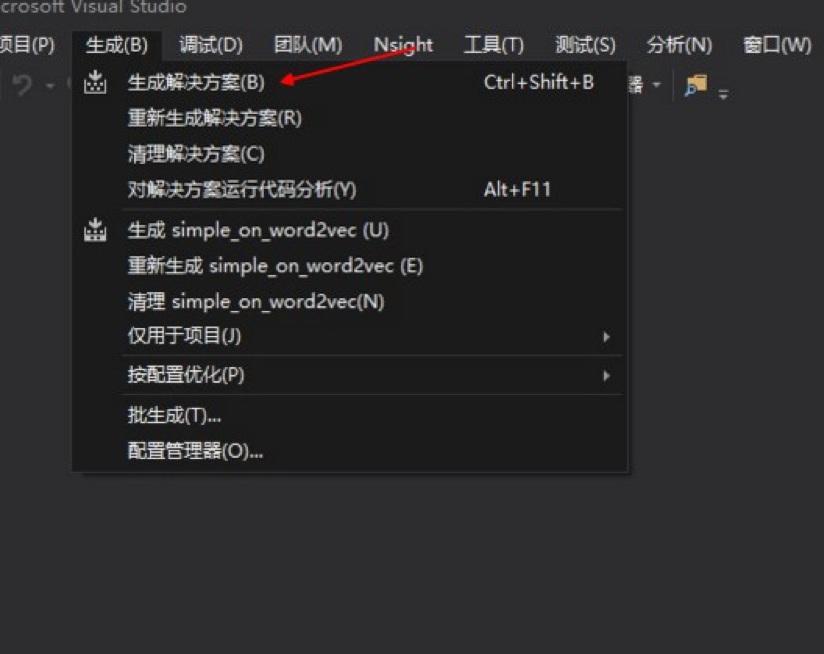
通过cmd进到Release目录执行:
- 开启GLOG
`set GLOG_v=100`
- 进行预测
`simple_on_word2vec.exe --dirname=.\word2vec.inference.model`